Demystifying AutoML

At Bounteous, we are firm believers in data-driven decision making. Who are your customers? Is your customer base increasing or decreasing? Why are they leaving, and who is most likely to leave next? These questions are relevant in many different industries, and businesses invest heavily in answering them. Data science teams are working to turn many forms of first-party data ranging from transactions, to customer addresses, to marketing spends across different platforms and channels into predictive models that provide actionable insights. In addition, the last decade has seen a rise in data science / machine learning platforms that aim to answer these same questions through an automated and code free approach.
A 2019 article famously (or infamously?) went so far as to pose the question “Will AutoML Replace Data Scientists?” (See “The Death of Data Scientists”). As of August 2022, the answer is a firm “no." Data-driven consulting and data science solutions remains more in demand than ever before. But, to the article's initial point, the topic of “AutoML”, is equally alive and well. So, what is it? And, does your organization need it?
“AutoML” is a reference to the process of automating machine learning tasks and model development. There is a variety of code free options that exist, as opposed to coding machine learning models from scratch. Cloud platforms including Google Cloud Platform (GCP), Amazon (AWS), or Microsoft Azure usually have varying AutoML capabilities to build, train and deploy models.
To help demonstrate how straightforward the process of building a model in Google’s AutoML interface is, Bounteous will attempt to solve a common business problem by building a customer churn model in Google Cloud Platform’s Vertex AI, using their codeless model building route, coincidentally also named “AutoML”, (all future references to “AutoML” will be specific to GCP Vertex AI). If you would like to learn more about the process, feel free to pull up GCP and follow along! For this specific example Bounteous will be using the publicly available Telco Churn Dataset. The results will then be compared to a variety of machine learning classification models built with Python’s scikit-learn.
Customer churn, in this use case, is defined as a customer choosing to cancel a subscription. The ability to predict customers who are likely to churn/leave is extremely important. If you know which customers are likely to leave soon, you can employ a marketing strategy to retain them. Retaining customers is almost always more cost efficient than finding new ones. Identifying likely churners is a great way to increase profitability for any organization. This article covers one of many different data science modeling techniques Bounteous utilizes to help our clients increase efficiency and profitability.
To build the churn model in GCP Vertex AI’s AutoML, the first step is to upload a dataset. In GCP, both structured and unstructured data can be uploaded. An example of structured data would be a CSV file with rows and columns, while unstructured data might be a collection of images or text.
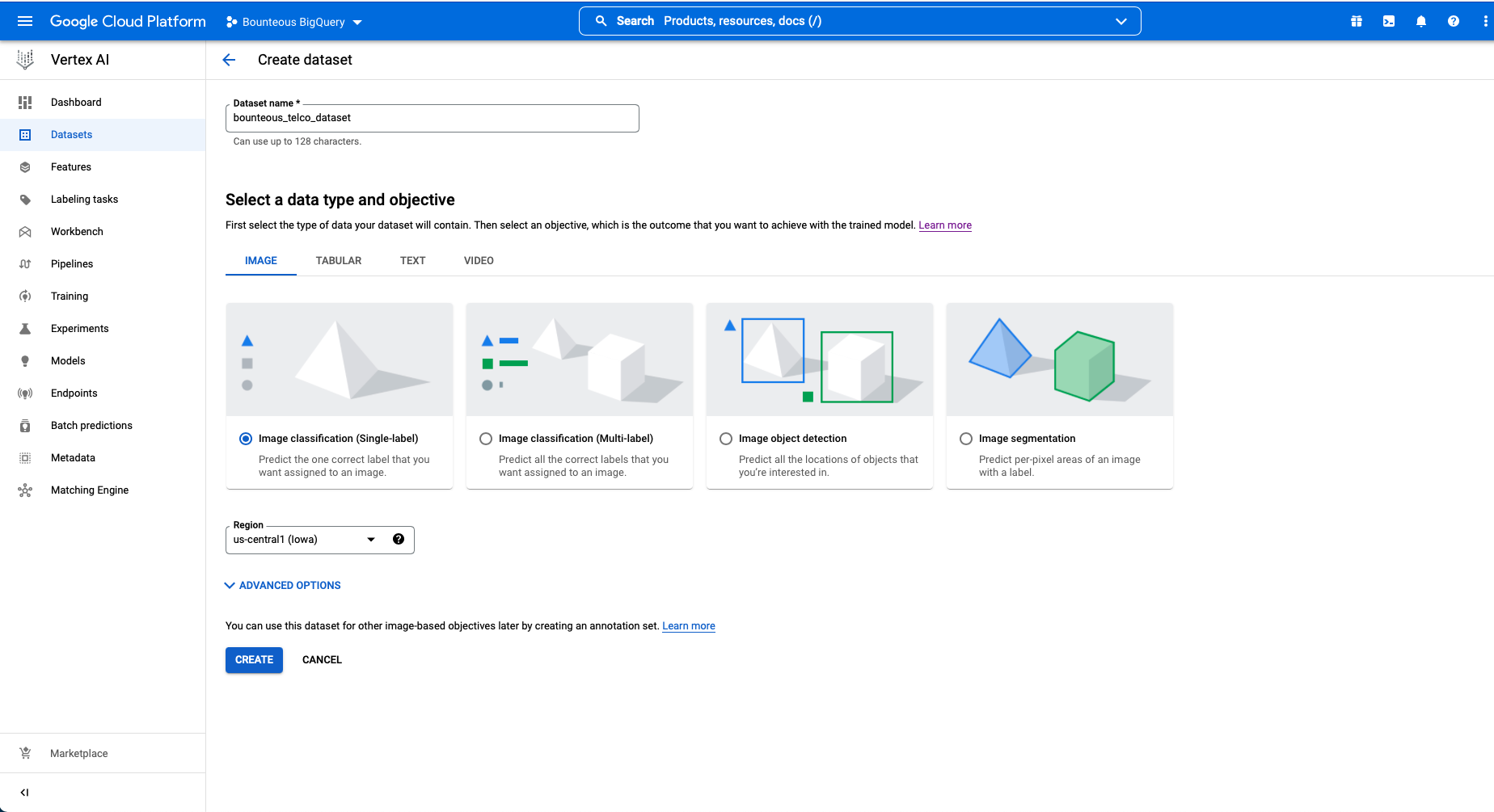
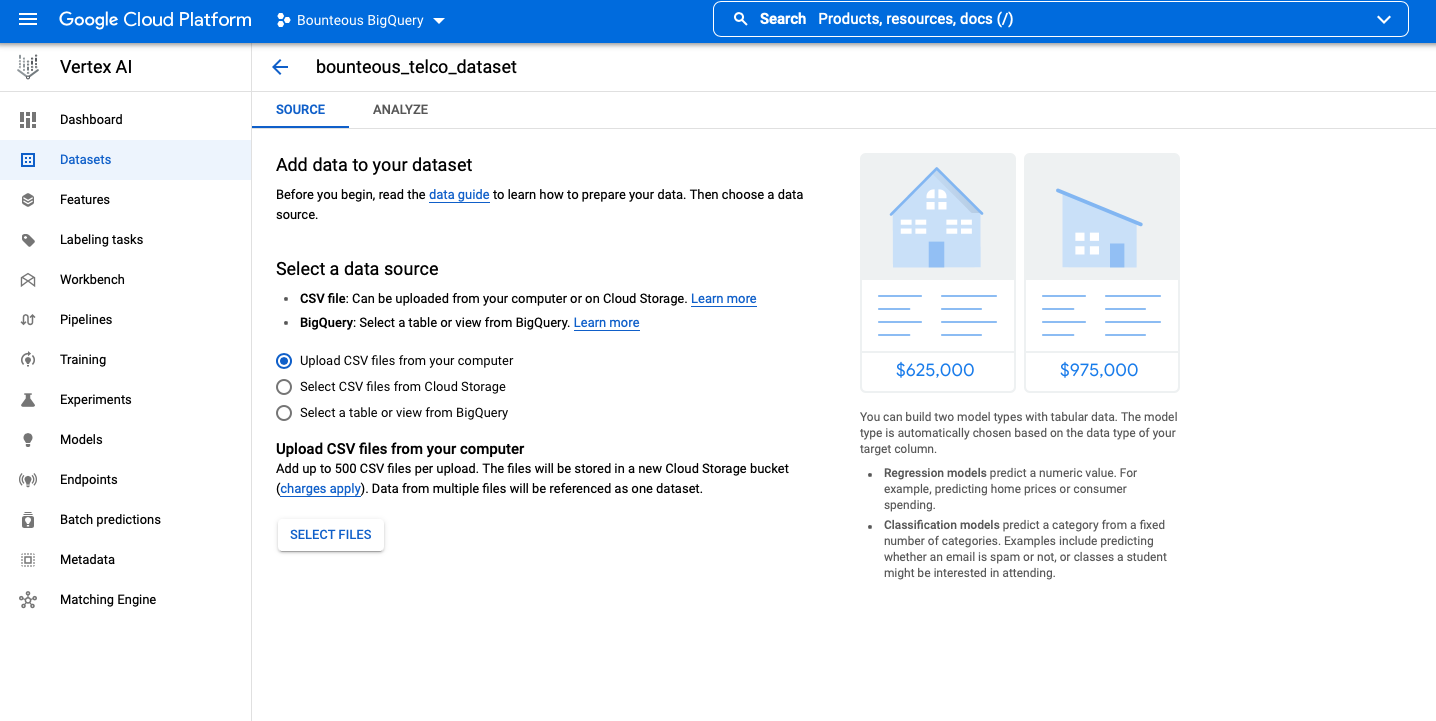
Once the dataset is loaded into GCP, the model can now be trained. In this example that predicts a binary outcome, a classification model will be trained.
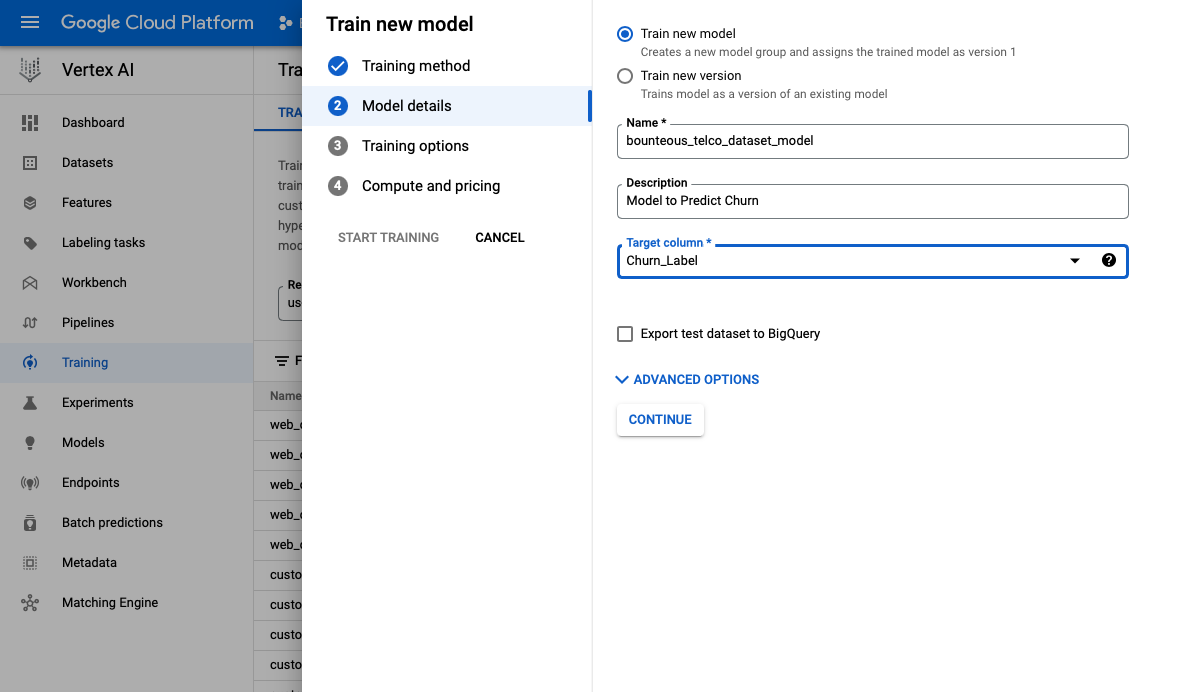
Under model details, our team would specify a target column as “Churn_Label”, which in this dataset is the binary outcome of “yes” or “no”.
The next step is to specify both numeric and categorical fields that the model would use to predict (listed below).
| Field Name | Field Type |
|---|---|
| Contract | Categorical |
| Dependents | Categorical |
| Internet Service | Categorical |
| Monthly Charges | Numeric |
| Tenure Months | Numeric |
| Payment Method | Categorical |
| Total Charges | Categorical |
| Multiple Lines | Numeric |
| Online Security | Categorical |
| Streaming TV | Categorical |
| Tech Support | Categorical |
| Online Backup | Categorical |
| Paperless Billing | Categorical |
| Partner | Categorical |
| Streaming Movie | Categorical |
| Device Protection | Categorical |
| Phone Service | Categorical |
| Gender | Categorical |
| Senior Citizen | Categorical |
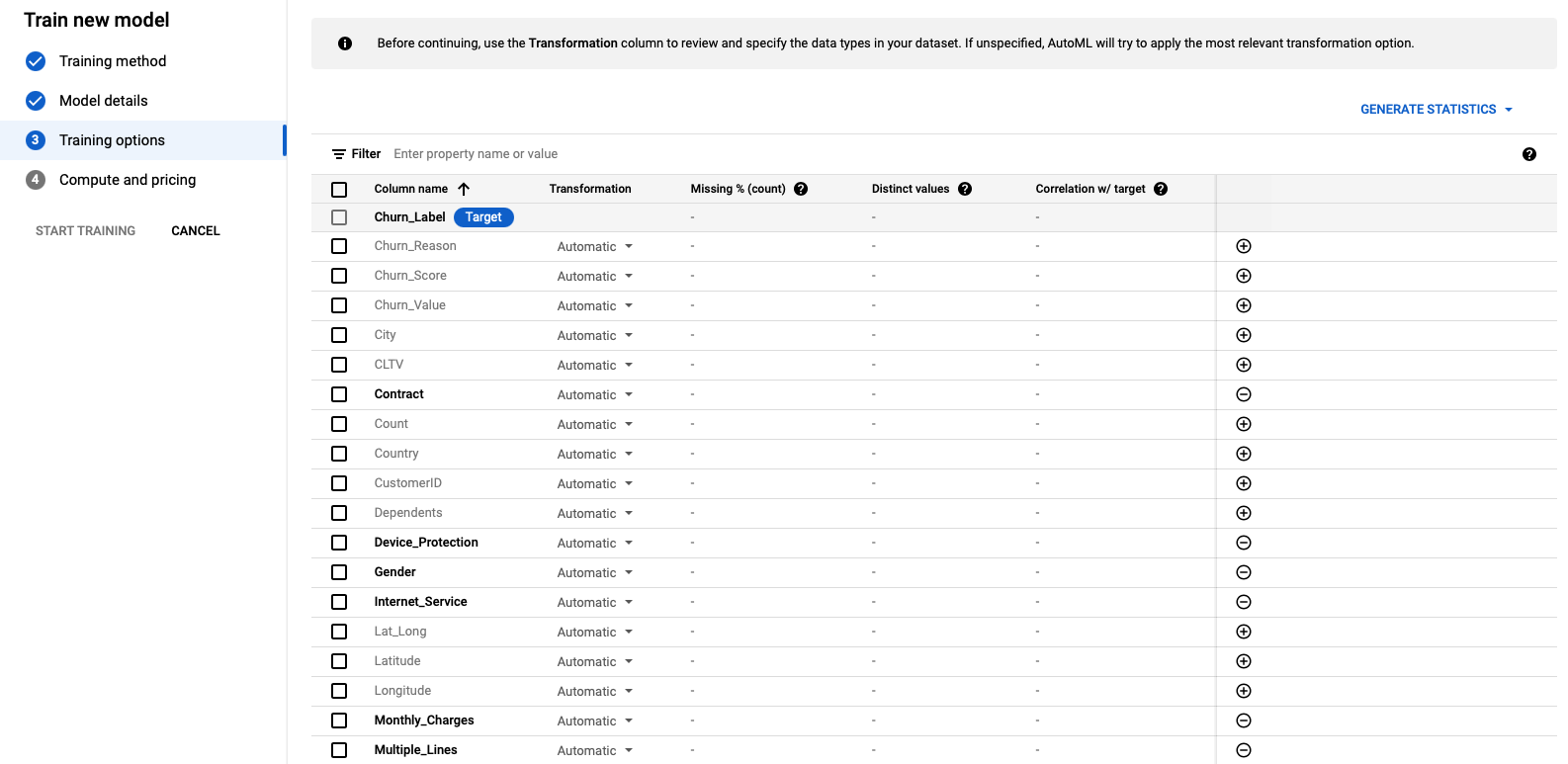
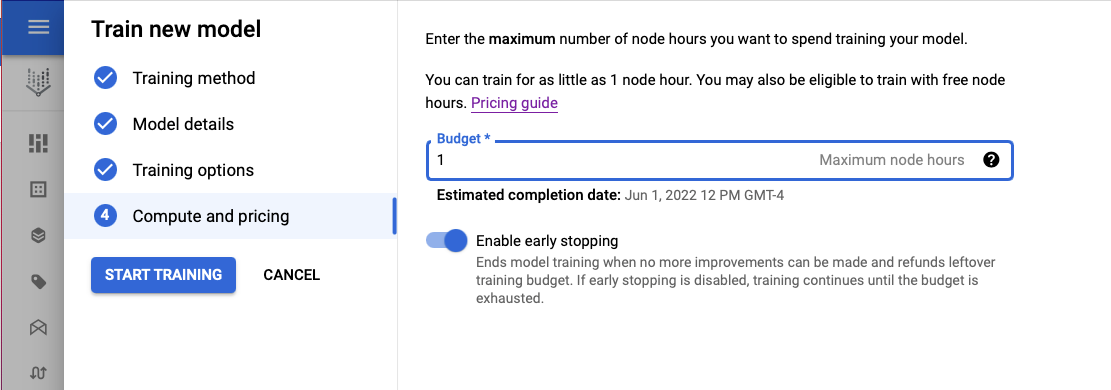
This model takes 1-1.5 hours to run.
The costs associated with training a model on Vertex AI are described below.
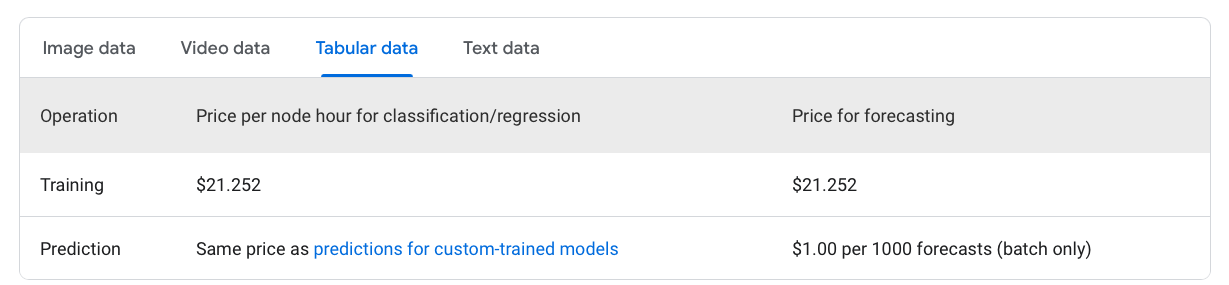
An email will be sent to the user when the model is complete, allowing the business to dive into the results.
When it comes to classification algorithms, there is a standard set of metrics that are used to evaluate the quality of a model. These metrics can all be derived from something called a confusion matrix. A confusion matrix is a technique/tool allowing us to understand the effectiveness of a classification system. It is a 2x2 table that consists of actual vs. predicted outcomes. In the first quadrant, “True Positive” indicates a result that was both Positive and Predicted (think actual churned customer and predicted churned customer), while “True Negative” would be Predicted Negative and Actual Negative. In addition, it also contains the “False Positive” and “False Negative” metrics.
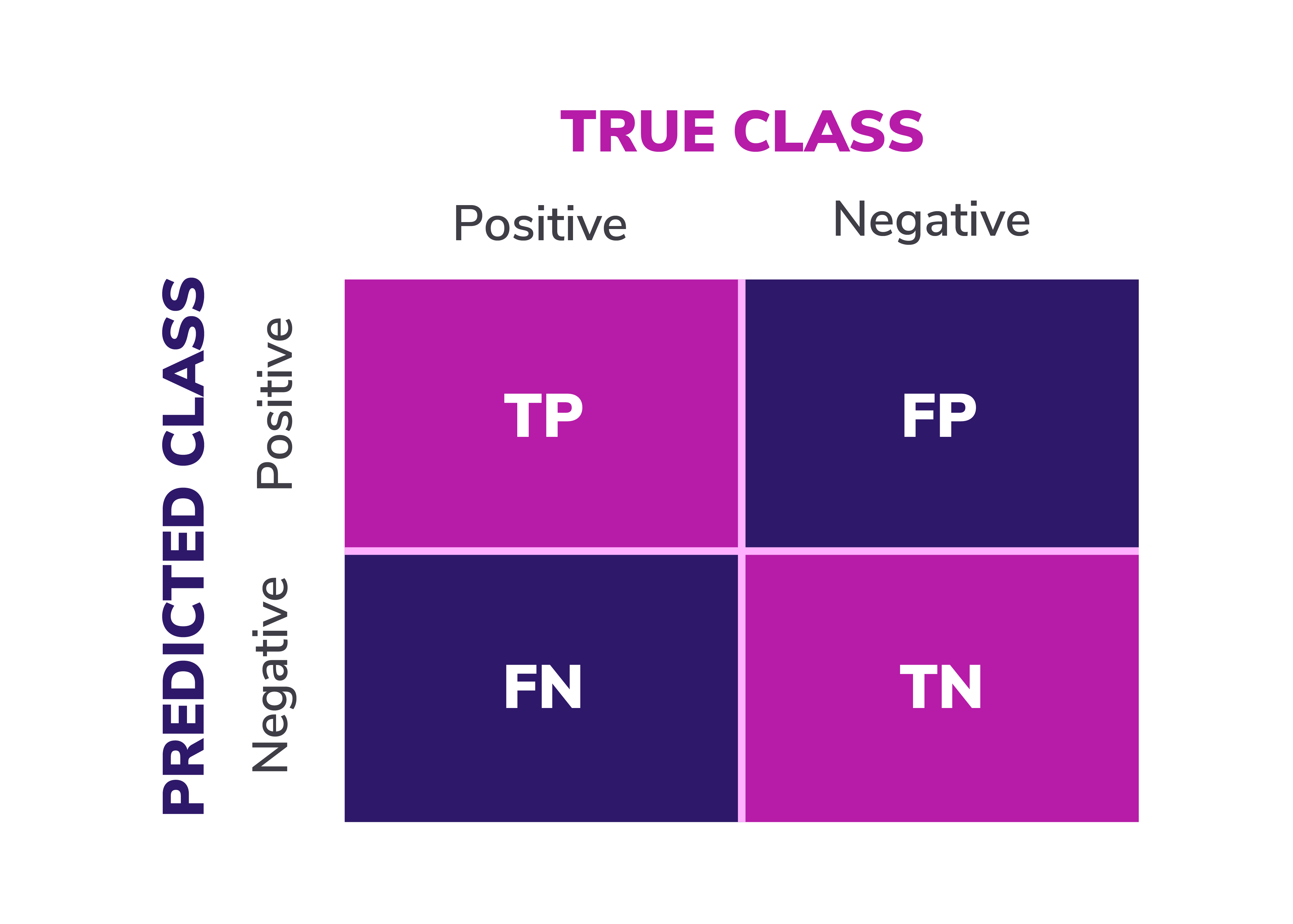
The confusion matrix from our GCP model is shown below.
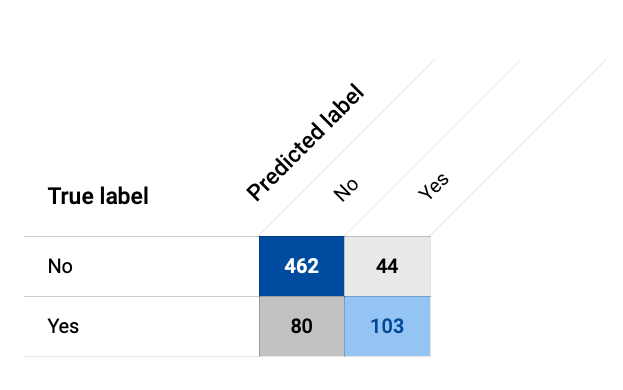
From the confusion matrix, two important metrics can be calculated to provide better insights into the prediction: precision and recall. These are defined as follows:

So, one might wonder, which metric is more important - precision or recall? The answer depends on the objective. A model that favors a strong precision score is desired when trying to minimize false positives. An example of this could be a model that predicts age-appropriate movies for children where it only pulls appropriate ones, while filtering out everything else that is deemed inappropriate. On the other hand, a model that favors a strong recall score is desired when trying to minimize false negatives. An example of this would be a model that detects fraud - a credit card company would likely prefer to make a few extra phone calls to confirm purchases, rather than letting actual credit card fraud go unnoticed.
It is sometimes easier to combine precision and recall into one simplified metric (F1 score).
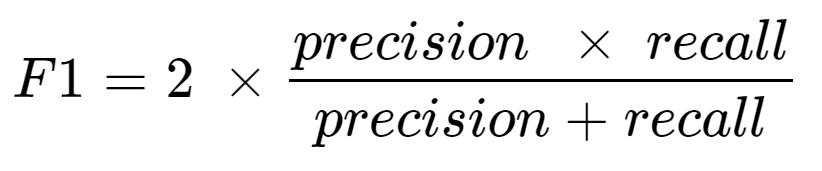
The F1 score is the harmonic mean of precision and recall, meaning the F1 score will only produce a high F1 score if both precision and recall are high. Below, the metrics have been provided from the GCP Vertex AI AutoML churn model:
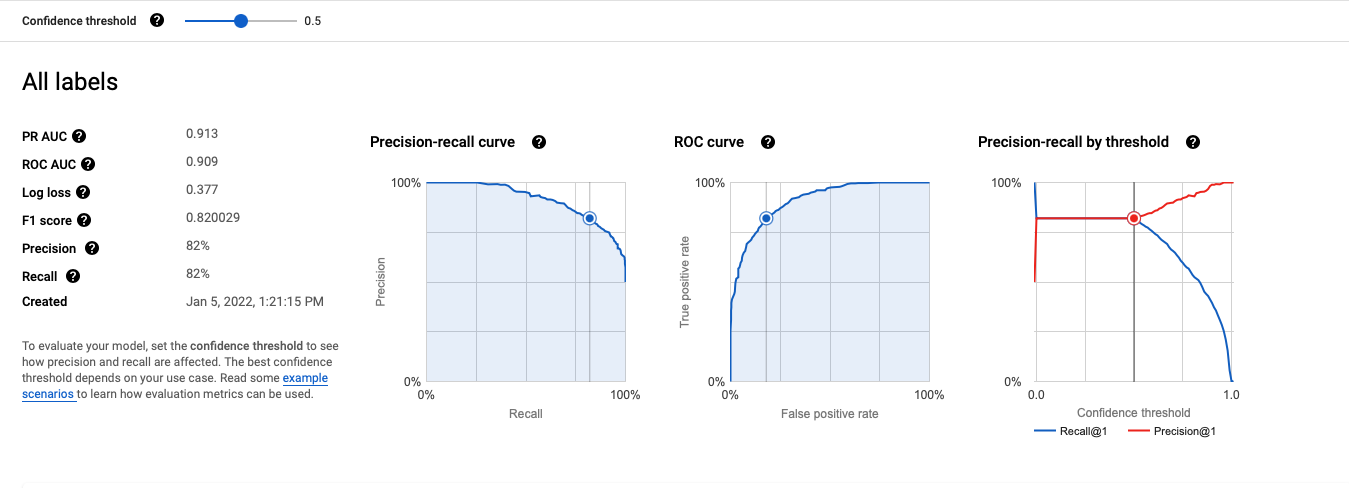
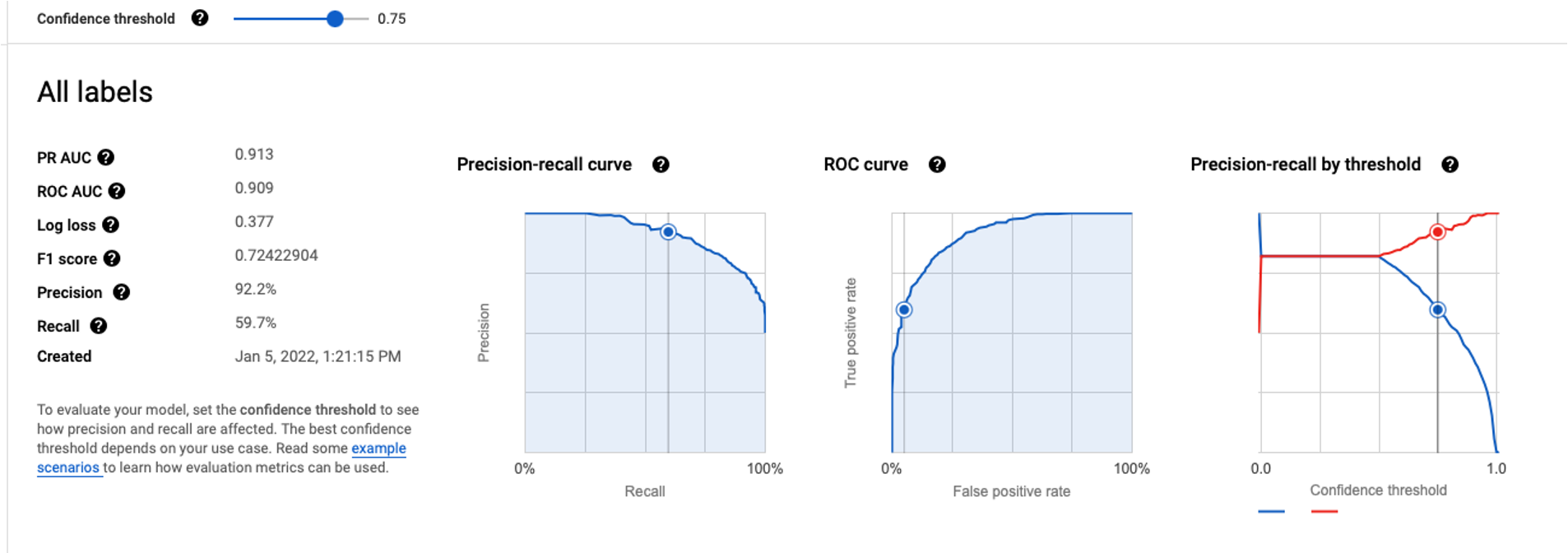
The “Confidence Threshold” is the point at which the predicted probability our customer churned is considered a predicted churn or no churn. In the visual shown above, confidence threshold of 50% indicates that if the predicted probability of churning for an individual customer is greater than 50%, our model predicts this customer will have churned. If a higher confidence threshold is desired, we would want to identify customers we are very certain will churn, thus our precision and recall calculations will change.
GCP AutoML also allows visibility into which features in this model are most important via a feature importance graph (shown below).
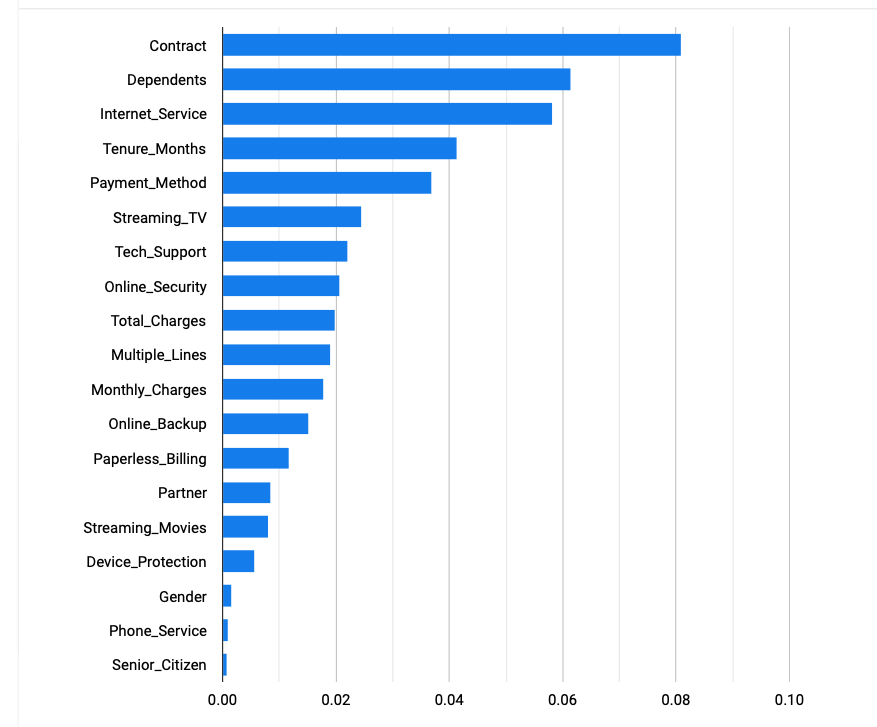
The two key features in this model are “Contract” and “Dependents." Both are categorical fields, options being (“Month-to-month", “One year” and “Two year”) for Contract and (“Yes”,”No”) for Dependents.
The Bounteous Data Science team built out six different classification models through a variety of algorithms within Python's scikit-learn package, and determined they were in line with AutoML model predictions.
| Precision | Recall | F1 | |
|---|---|---|---|
| GCP Vertex AI AutoML | 0.82 | 0.82 | 0.82 |
| Logistic Regression | 0.9 | 0.82 | 0.86 |
| Support Vector Machines | 0.92 | 0.75 | 0.83 |
| Decision Trees | 0.72 | 0.76 | 0.74 |
| Random Forest | 0.81 | 0.83 | 0.82 |
| Naïve Bayes | 0.82 | 0.83 | 0.83 |
| K-Nearest Neighbor | 0.71 | 0.8 | 0.75 |
The results for Precision, Recall and F1 are comparable to the Vertex AI AutoML model. The models built in scikit-learn were done using the same variables that were utilized in Vertex AI, with no additional feature engineering or parameter tuning. Feature engineering is the process of obtaining new variables from existing variables that can be used in the model. An example of this might be a variable, or set of variables, that explores the relationship between the Contract and Dependents fields, our two highest ranking predictors. This would allow us to answer questions such as “Are customers who are on “Month to Month” contracts and “Yes” to dependents more indicative of churn than customers who are on “One year” contracts and have no dependents?” From feature engineering, a feature not available in GCP Vertex AI AutoML, we would be able to incorporate these types of predictors into our model, which is often necessary for more challenging datasets.
AutoML users also have the option to select a more advanced approach, by choosing to build their model with the “Custom training (advanced)” method for model building. While GCP AutoML provides the ability to build a model with little expertise needed, the custom training route would require a more experienced hand in developing.
A model, such as this, would add substantial value to an organization. If we know customers who are likely to churn, preventative measures can be taken to reduce this risk. We can incentivize them with deals through a targeted mail/email campaign or reach out to discuss customer satisfaction and ways to improve it via a service line. It is almost always more efficient to retain a customer than to acquire a new one.
When it comes to building machine learning models, often the devil is in the details of how these models are built, with respect to their quality. The AutoML in GCP Vertex AI, as well as many other codeless machine learning models, can be a bit of a black box when it comes to details of how the model’s parameters are defined and how the dataset is sampled to build the model. In some cases, “AutoML” may be enough for your organization’s modeling need, but in other cases a more advanced approach might be needed.
Organizations now have many options for building out machine learning capabilities. At Bounteous, we employ a combination of GCP Vertex AI capabilities and proprietary algorithms to develop machine learning models specific to our clients’ needs. Custom trained models allow us to have complete control over our model building process.
At Bounteous, our team of Data Scientists and Data Engineers work with clients to identify and address their most pressing business questions and needs. While the dataset used in the model described above is immediately ready to be modeled, this is often not the case in data science/engineering work. We find that real world data almost always comes from a variety of different sources and formats and often requires many hours of data munging and formatting prior to a point where it can be uploaded to AutoML and modeled.
There is no magic data science platform where we can upload 20 different CSV files or connect to a variety of data sources that are associated with different levels of granularity. For example, weekly vs. daily vs. hourly time series data, or retail location vs. regional vs. zip code level geographic data. Common data wrangling tasks, such as knowing when to impute missing values versus knowing when a null value implies a value of 0 on a case-by-case scenario, continues to require human intervention.
Automated Machine Learning is not the only solution to the data science life cycle. At Bounteous, these platforms are used as tools of trade and employed when it is in the best interest of our clients. We work with marketing and eCommerce data across a variety of different platforms (Google, Adobe, Meta/Facebook, Amazon, Microsoft etc.). A large part of Bounteous work involves engaging with clients to identify how to best leverage the insights data science models can provide, that ultimately lead to actionable business decisions.
News & Insights
Related Perspectives


