Configuring Automated Data Export in Adobe Experience Platform

Adobe Experience Platform (AEP) has a wide array of native source connectors for data ingress into the platform as well as a number of native destination connectors to publish data to various marketing destinations, enabled by the Real-Time Customer Data Platform (RTCDP). However, it is not uncommon to require data egress outside of the typical marketing activation use case that the RTCDP feature provides.
The Many Ways of Exporting Data from AEP
First, let’s take a look at the platform architecture and number all the different methods of extracting data from platform.
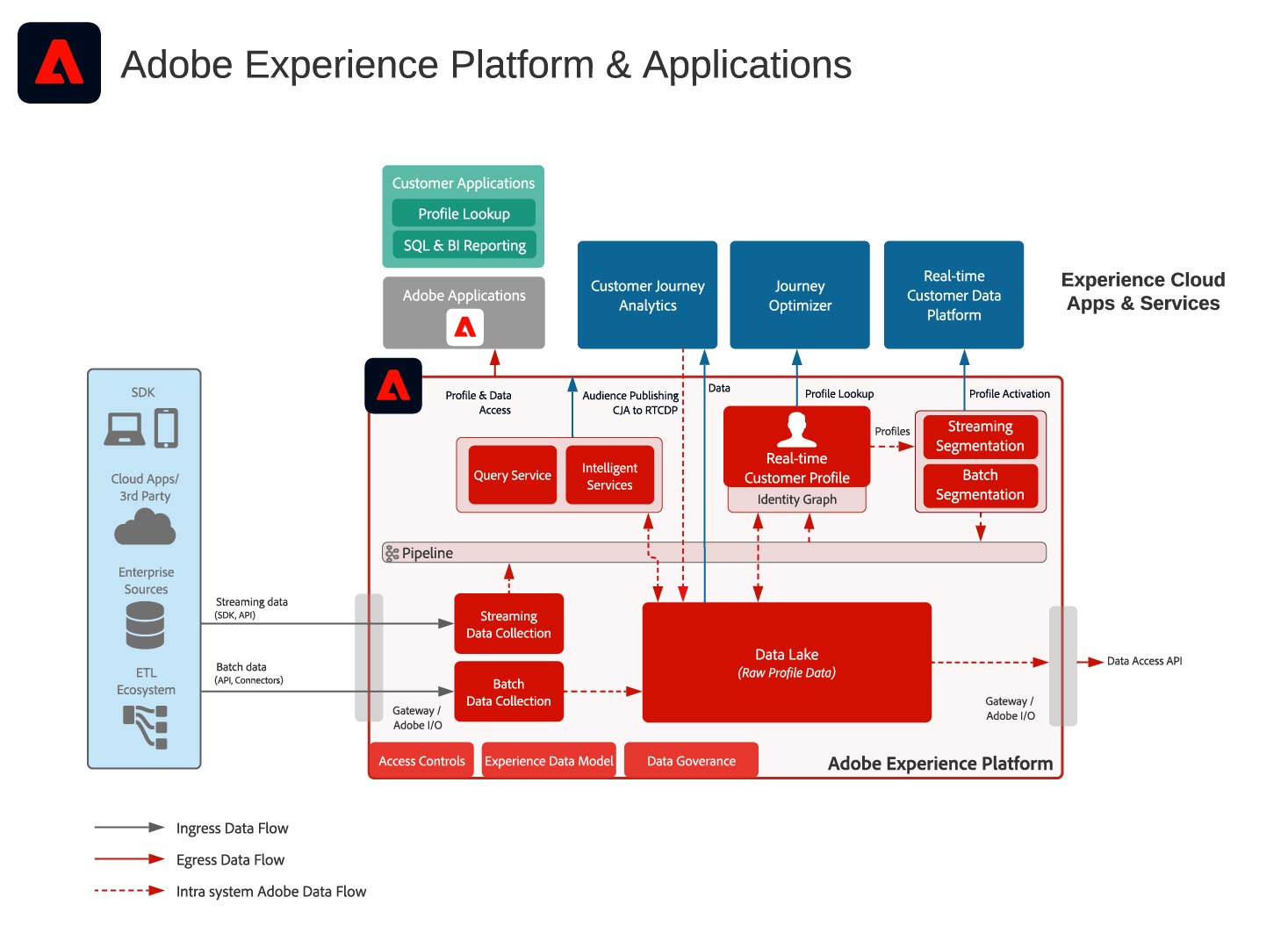
- Real-time Customer Data Platform - typical use case for marketing activation, e.g., sending profiles to Facebook, Google
- Profile Lookup - using a known identity, lookup a single profile
- Query Service - query the data lake using Postgresql client. Typically used for adhoc analysis or connecting to a BI reporting tool
- Data Access API - bulk export of data from the data lake
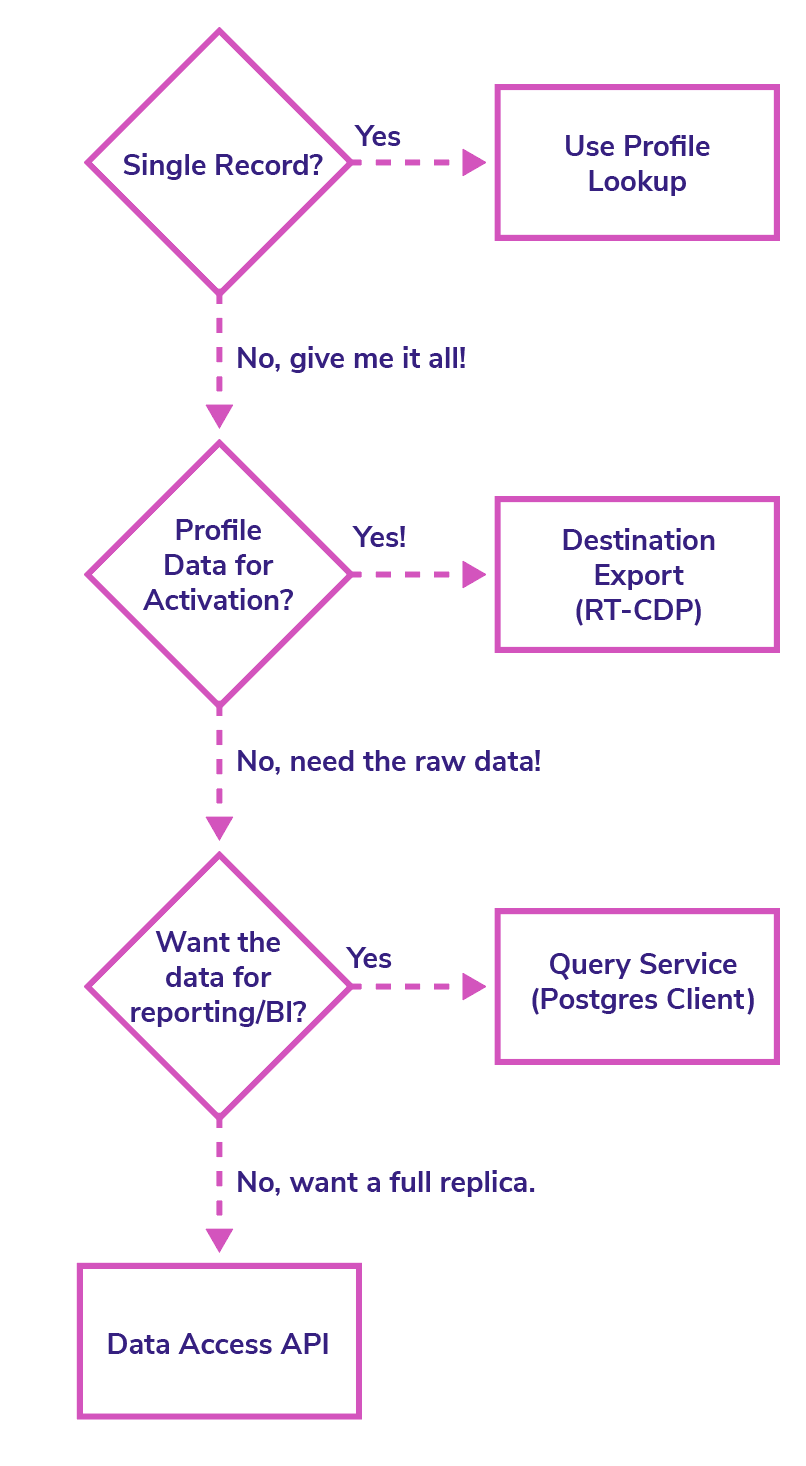
As you can see there are a lot of options for data exports, and at first glance it can be daunting trying to figure out which method or combination of methods is the right fit. I put together a quick decision tree diagram that shows how we would decide which method fits a particular use case.
Hopefully that helps bring some context - the rest of the article we’re going to dive deep into one of the most powerful but yet complicated methods, the Data Access API, and actually put together a proof of concept! Adobe has a great tutorial on how to use the Data Access API to retrieve data from its Data Lake. In their tutorial, they show how to retrieve the data by polling the data access API (see diagram below), which absolutely works but stops short of a fully automated data pipeline. An ideal data pipeline uses a push-pull mechanism to retrieve the new data as it is loaded. We can accomplish this by combining the data access API with another feature, a webhook. The Adobe Webhook will allow us to subscribe to events in the Experience Cloud, in this Experience Platform and then use our own process to react to those events.
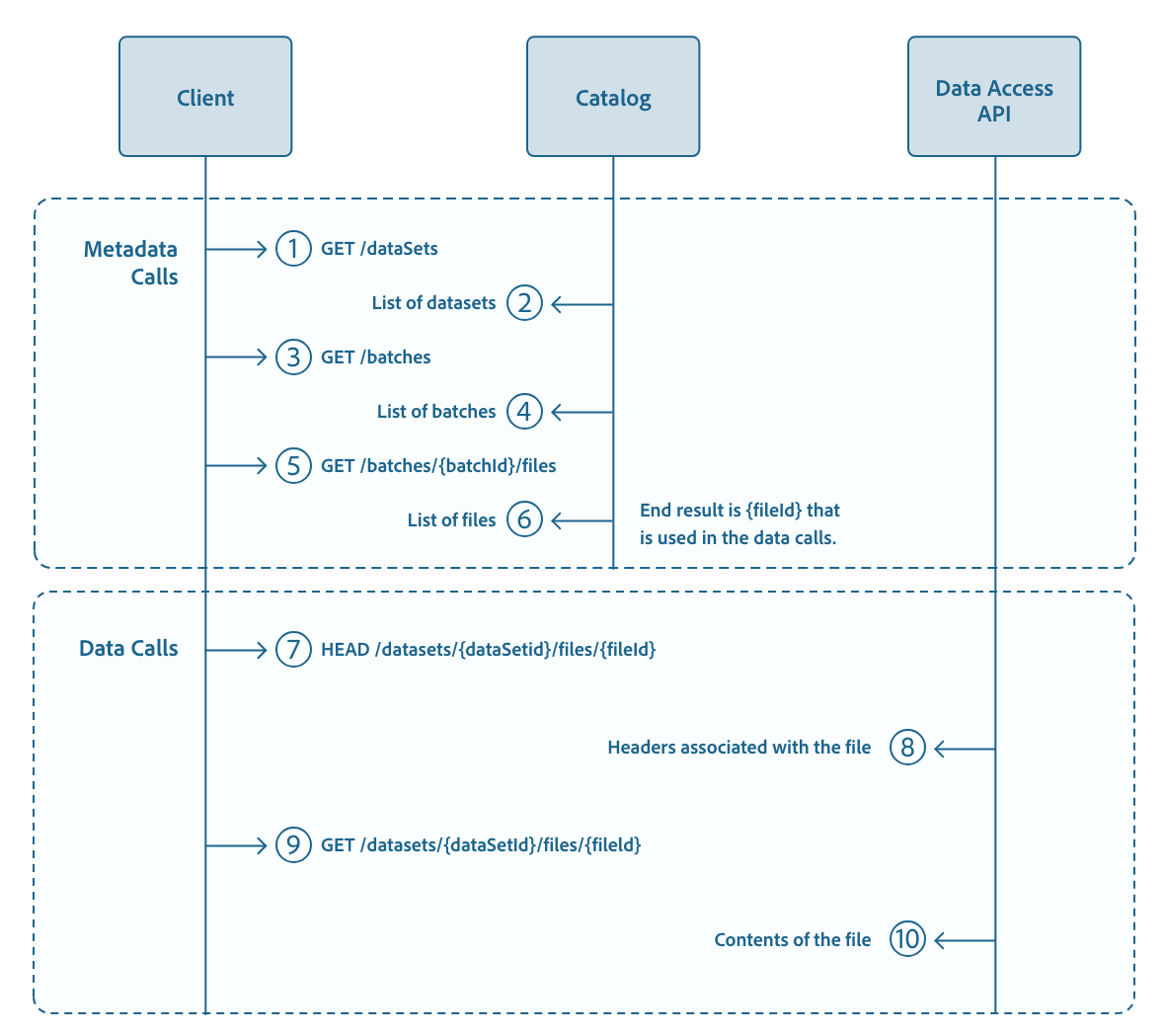
We’re going to walk through creating a proof of concept using a webhook and combine that with the data access API to create an automated data export pipeline from AEP into Google Cloud Platform (GCP). Note, this tutorial is using GCP because I personally wanted to learn more about GCP, but everything here can apply to other major cloud providers.
Creating an Automated Export Process
1. Create a Project in The Adobe Developer Console
First, we need to go to Adobe’s Developer Console. Contact your Adobe administrator to be granted Developer access on AEP if you do not already have it. If you already have an existing project, feel free to jump ahead.
2. Create API Project
3. Webhook Event
For this, you’ll need two components added to your project, “Event” (for the Webhook) and “API” (for the Data Access API). Let’s start with adding the Webhook Event to the project.
Your new project will be created with an automatic name, let’s give that a meaningful name first, then select “+Add to Project” and select Event.
This will open the “Add Events” overlay. Next, select “Experience Platform” and then “Platform Notifications”.
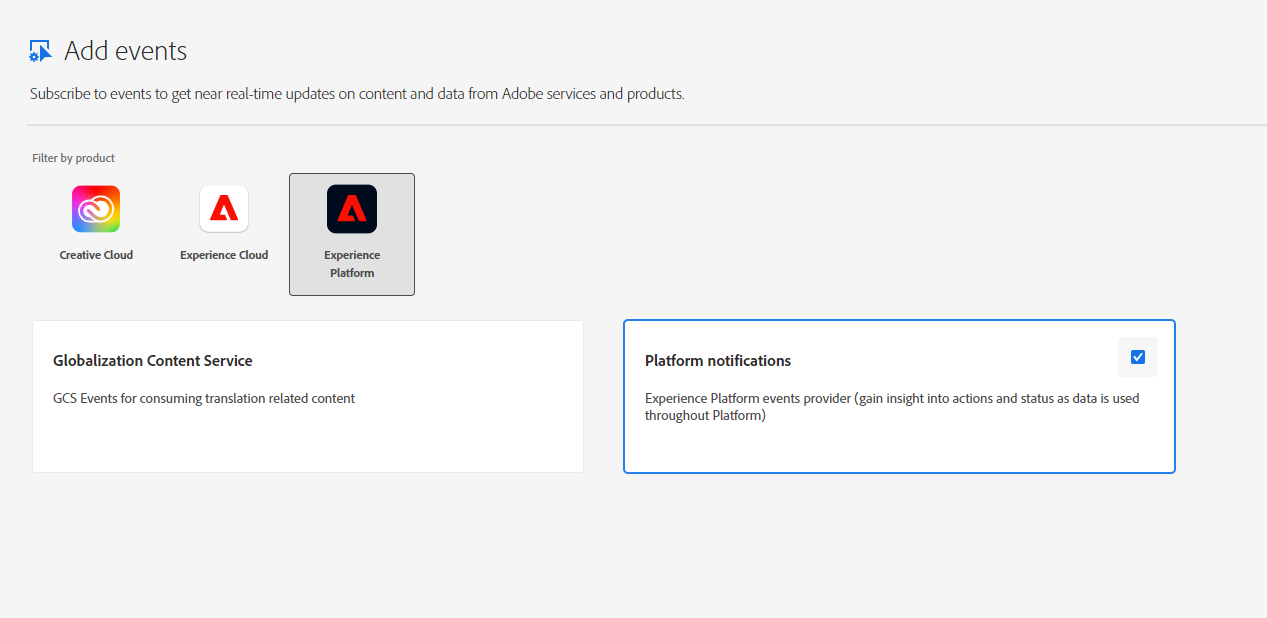
On the next screen, you have a number of different events to subscribe to - for our purposes here, select “Data Ingestion notification”, which will give us information on new data ingested into the AEP data lake.
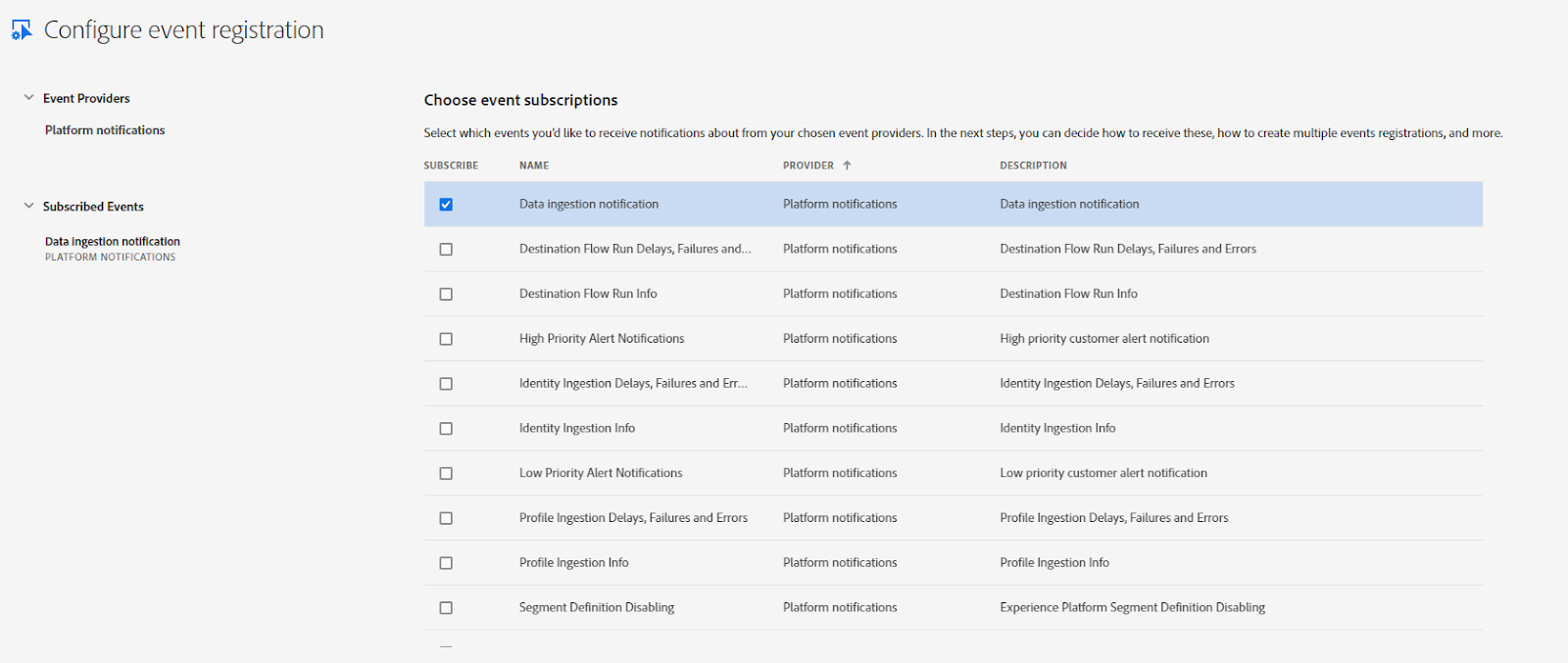
On the next screen it will ask for a webhook URL. This is optional, but recommended, to set up a webhook via webhook.site so you can see the typical webhook payload. This article from Adobe has a good tutorial on setting that up. If you want to wait until the actual webhook is created and running, then just put in a dummy URL here and save it.
4. Add Experience Platform API
Now, let’s add the AEP API to the project. Start by hitting the “+ Add to Project” and this time select “API”. This is required as you need an API project with credentials to access the data access API.
On the pop-up, select Adobe Experience Platform and then check the “Experience Platform API”.
The next couple of screens will ask to either choose an existing key or upload a new one, then assign this API to the appropriate product profile. Choose the appropriate options for your situation and hit ‘Save’ at the end of the workflow. If you decide to generate credentials, make sure to store them in a secure location, as we will need those later.
5. Proof of Concept Solution Architecture
Below is a basic diagram that shows what we’re going to use in Google Cloud Platform (GCP) for this PoC and it starts by using a Google Cloud Function to host the Webhook endpoint. This function will listen for requests from the Adobe.IO Event Subscription and for each request, write the payload to BigQuery table then publish the Adobe Batch ID to a Pub/Sub topic.
We then have a second cloud function that’s subscribing to the Pub/Sub topic, performs the data retrieval from AEP, and writes the data to a Google Cloud Storage bucket.
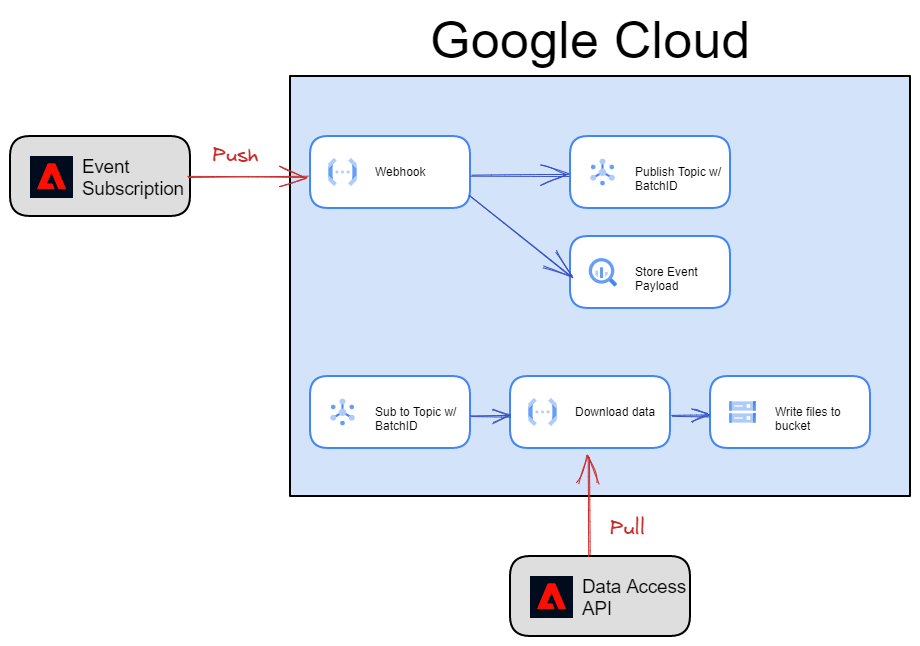
This proof of concept is written in Python because that’s my language of choice and you can find all the code in this post on Github. I’ve also put all the GCP command lines (CLI) to create the gcp resources in the associated readme files on Github.
Another sidenote, for this PoC I chose to use the new Gen2 Cloud Functions and as of writing they are still in beta. If you prefer gen1 functions, remove the beta and –gen2 from the CLI commands. This article from Google has a good explainer on the differences between the versions.
With that out of the way, let’s get started with this actual proof of concept!
To start with, let’s take a look at a sample Event Subscription payload –
{
"event_id": "336ea0cb-c179-412c-b355-64a01189bf0a",
"event": {
"xdm:ingestionId": "01GB3ANK6ZA1C0Y13NY39VBNXN",
"xdm:customerIngestionId": "01GB3ANK6ZA1C0Y13NY39VBNXN",
"xdm:imsOrg": "xxx@AdobeOrg",
"xdm:completed": 1661190748771,
"xdm:datasetId": "6303b525863a561c075703c3",
"xdm:eventCode": "ing_load_success",
"xdm:sandboxName": "dev"
},
"recipient_client_id": "ecb122c02c2d44cab6555f016584634b"
}The most interesting piece of information here is the event.xdm:ingestionId, as that appears to be the AEP batch_id. It also has the sandboxname and datasetId which will both be useful for retrieving the data from the data lake. You can find Adobe’s documentation on the Data Ingestion Notification payload here.
[Optional] Create BigQuery Table
This is optional but as someone that has worked with data systems for many years, having a simple log table with what’s been processed can really save you later. In this case we’re just doing some light transformation and storing the payload of the payload in BQ.
bq mk \
--table \
mydataset.event_log \
schema.json*Note* You can find the schema.json file in the webhook folder in the Github repo.
6. Webhook Function
First, a quick pre-requisite, create a new Pub/Sub Topic that the function will publish to -
gcloud pubsub topics create aep-webhookWith that created, clone the code from GitHub, navigate to the webhook directory sub-directory and then deploy as a cloud function:
gcloud beta functions deploy aep-webhook-test \
--gen2 \
--runtime python39 \
--trigger-http \
--entry-point webhook \
--allow-unauthenticated \
--source . \
--set-env-vars BQ_DATASET=webhook,BQ_TABLE=event_log,PUBSUB_TOPIC=aep-webookOnce the deploy completes, jump into the GCP console, navigate to Cloud Functions and you should see your new function, aep-webhook-test deployed. Copy the new URL -

Then jump back over to the Adobe Developer Console and put this URL your Webhook URL –
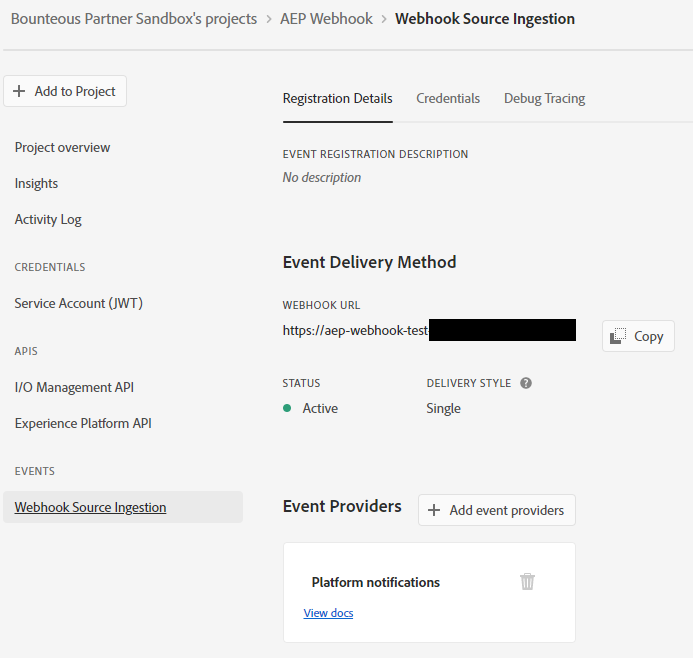
You should see an immediate request to the new webhook function with a challenge parameter. If everything deployed correctly, then the new function will respond with the challenge response and the Adobe Console will show its status as “Active”. If not, then a good place to start is the Debug Tracing tab, it will show you the exact request Adobe sent and the response it received.
7. Data Processing Function
With the webhook function up and running, let’s move on and deploy the data processing function.
Let’s start with creating the Storage Bucket to land the data -
gsutil mb gs://[yourname]-aep-webhook-pocIf you’ve cloned the code from Github, change directory to subscribe-download-data, create a credentials folder and drop the credentials that were created earlier in the Adobe Developer Console. Note: this is just done for the PoC and it is recommended to use a KMS (Key Management System) to store credentials for a real production pipeline.
gcloud beta functions deploy aep-pubsub-function-test \
--gen2 \
--runtime python39 \
--trigger-topic aep-webook \
--entry-point subscribe \
--source . \
--memory=512MB \
--timeout=540 \
--set-env-vars GCS_STORAGE_BUCKET=[yourname]-webhook-pocIf everything runs correctly, after a few minutes you should see the function show up in your GCP Cloud Functions.

Depending on how busy your AEP environment is, it might take a few minutes to a couple hours for data to start appearing in the storage bucket.

You’ll notice that all the files are somewhat cryptically named parquet files. This is the native format that is stored inside the AEP data lake.
After The Export
And with that, we have a simple pipeline that will automatically download and store the .parquet files that are created in the AEP data lake. Obviously, we just scratched the surface of what is possible with the combination of the event registration (webhook) and the data access API. A few ideas I had while working through this process –
- Land the files within a sub-folder per sandbox in the GCS bucket
- Use the API to lookup the name of the dataset associated with the parquet file to rename it to something more user friendly
- Add a failed ingestion path in the code to automatically download the failed data into a separate location and send notifications
Exporting data outside of AEP allows us to consider multiple use cases and activations, and from this demonstration, can be completed by following some clearly outlined steps. I hope this tutorial was instructive and easy to follow, and perhaps inspires a few new use cases for data activation!


